





A história por detrás do Barracuda Active Threat Intelligence
Há algum tempo, numa das nossas sessões de brainstorming, enquanto as equipas discutiam o próximo nível de evolução dos nossos produtos, tornou-se evidente que a deteção e proteção contra novas e emergentes ameaças exigiam uma análise intensiva de dados em grande escala. A análise precisaria prever o risco dos clientes e fazê-lo de forma eficiente e rápida, caso quiséssemos evitar que ações hostis ocorressem.
Ao analisarmos os requisitos, percebemos que, para proteger contra atacantes avançados como bots, precisávamos construir uma plataforma que pudesse analisar o tráfego das sessões web, correlacioná-lo com dados entre sessões e, para muitas coisas, em toda a base de clientes. Também descobrimos que muitas partes do sistema precisavam de ser em tempo real, algumas quase em tempo real e outras poderiam ter uma fase de análise muito mais longa.
Há alguns anos, introduzimos o Barracuda Advanced Threat Protection (BATP) para proteção contra ataques de malware zero-day em toda a linha de produtos Barracuda. Esta funcionalidade — analisar ficheiros para detetar malware utilizando vários motores além de sandboxing — foi introduzida nos produtos de segurança de aplicações da Barracuda para proteger aplicações como sistemas de processamento de encomendas onde os ficheiros eram carregados por terceiros. Esta foi a primeira tentativa de utilizar uma camada baseada em nuvem para análises avançadas que seriam difíceis de incorporar em appliances de web application firewall.
Embora a camada cloud BATP pudesse lidar com milhões de verificações de ficheiros, precisávamos de um sistema que pudesse armazenar grandes quantidades de meta-informações para que pudessem ser analisadas para descobrir ameaças novas e em evolução. Isto iniciou-nos na jornada em direção à próxima plataforma de inteligência de ameaças.
Como funciona o Active Threat Intelligence
A plataforma Barracuda Active Threat Intelligence é a nossa resposta. A plataforma é construída num enorme data lake, que pode lidar com o processamento de fluxo, bem como o processamento de dados em lote. Processa milhões de eventos por minuto, em várias regiões geográficas, e fornece inteligência utilizada para detetar bots e ataques do lado do cliente, além de fornecer informações para proteger contra esses vetores de ameaças. O Barracuda Active Threat Intelligence foi desenvolvido com uma arquitetura aberta para poder evoluir rapidamente e lidar com ameaças mais recentes.
Atualmente, a plataforma Barracuda Active Threat Intelligence recebe dados dos motores de segurança do Barracuda Web Application Firewall e do WAF-as-a-Service, assim como de outras fontes. À medida que os eventos são recebidos, são enriquecidos com feeds de ameaças obtidos por crowdsourcing e outras bases de dados de inteligência. A análise detalhada desses eventos, tanto individualmente quanto como parte de uma sessão de utilizador, é utilizada para categorizar os clientes como humanos ou bots.
Os pipelines de análise de dados utilizam vários motores e modelos de aprendizagem automática para analisar múltiplos aspetos do tráfego e chegar às suas recomendações, que são finalmente reconciliadas para produzir o veredicto final.
Maneiras como o Active Threat Intelligence ajuda a proteger as suas aplicações
Para além de suportar toda a análise necessária para a Proteção Avançada contra bots, a plataforma Active Threat Intelligence está a ser utilizada para as nossas mais recentes ofertas: Proteção do Lado do Cliente e o Motor de Configuração Automatizada.
O Active Intelligence de ameaça monitoriza quaisquer recursos externos que possam ser usados pela aplicação, como um JavaScript externo ou uma folha de estilo. A monitorização de recursos externos garante que estamos cientes da superfície de ameaças e que podemos proteger-nos contra ataques como o MageCart e outros.
Como os metadados que são recolhidos são extremamente ricos, podemos extrair informações adicionais deles para ajudar os administradores, fornecendo recomendações de configuração com base no tráfego real que chega às suas aplicações.
Esta plataforma tem sido instrumental para nos ajudar a construir a próxima geração de capacidades de proteção que os nossos clientes requerem. Continuamos a aproveitar esta plataforma escalável para reunir insights profundos sobre padrões de tráfego, consumo de aplicações e mais. Fique atento aos blogs das nossas equipas de engenharia que falarão sobre como criámos o Barracuda Advanced Threat Intelligence.

Anshuman Singh é Senior Director Product Management na Barracuda. Conecte-se com ele no LinkedIn aqui.
A evolução do pipeline de dados
O pipeline de dados é o pilar central das aplicações modernas intensivas em dados. No primeiro post desta série, vamos examinar a história do pipeline de dados e como essas tecnologias evoluíram ao longo do tempo. Posteriormente, descreveremos como estamos a aproveitar alguns desses sistemas na Barracuda, aspetos a considerar ao avaliar componentes do pipeline de dados e exemplos inovadores de aplicações para ajudá-lo a começar a construir e implementar essas tecnologias.

MapReduce
Em 2004, Jeff Dean e Sanjay Ghemawat da Google publicaram MapReduce: Processamento de Dados Simplificado em Grandes Clusters. Eles descreveram o MapReduce como:
“[…] um modelo de programação e uma implementação associada para processar e gerar grandes conjuntos de dados. Os utilizadores especificam uma função de mapeamento que processa um par chave/valor para gerar um conjunto de pares chave/valor intermédios, e uma função de redução que funde todos os valores intermédios associados à mesma chave intermédia.
Com o modelo MapReduce, conseguiram simplificar a carga de trabalho paralelizada para gerar o índice da web do Google. Esta carga de trabalho foi programada para um cluster de nós e oferecia a capacidade de escalar para acompanhar o crescimento da web.
Uma consideração importante do MapReduce é como e onde os dados são armazenados no cluster. Na Google, isto foi denominado Google File System (GFS). Uma implementação de código aberto do GFS do projeto Apache Nutch foi finalmente incorporada numa alternativa de código aberto ao MapReduce chamada Hadoop. O Hadoop surgiu no Yahoo! em 2006. (Hadoop foi nomeado por Doug Cutting em homenagem a um elefante de brinquedo que pertencia ao seu filho.)
Apache Hadoop: Uma implementação open source do MapReduce
![]()
O Hadoop alcançou grande popularidade e, em pouco tempo, os programadores começaram a introduzir abstrações para descrever tarefas a um nível mais elevado. Onde as funções de entrada, cartografia, combinador e redutor das tarefas eram anteriormente especificadas com muita formalidade (geralmente em Java simples), os utilizadores agora têm a capacidade de construir pipelines de dados usando fontes, sumidouros e operadores comuns com Cascading. Com o Pig, os programadores especificaram tarefas a um nível ainda mais elevado com uma linguagem específica do domínio totalmente nova chamada Pig Latin. Consulte a contagem de palavras em Hadoop, Cascading (2007), e Pig (2008) para comparação.
Apache Spark: Um motor de análise unificado para processamento de dados em grande escala
Em 2009, Matei Zaharia começou a trabalhar no Spark no AMPLab da UC Berkeley. A sua equipa publicou o Spark: Cluster Computing with Working Sets em 2010, que descreveu um método para reutilizar um conjunto funcional de dados em várias operações paralelas e lançou a primeira versão pública em março desse ano. Um artigo de acompanhamento de 2012 intitulado Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing ganhou o Melhor Artigo no Simpósio USENIX sobre Desenho e Implementação de Sistemas em Rede. O artigo descreve uma nova abordagem chamada Conjuntos de Dados Distribuídos Resilientes (RDDs), que permite aos programadores aproveitarem os cálculos na memória para alcançar aumentos de desempenho de ordens de magnitude para algoritmos iterativos como PageRank ou aprendizagem automática sobre o mesmo tipo de tarefas quando construídos no Hadoop.
Juntamente com as melhorias de desempenho para algoritmos iterativos, outra inovação importante introduzida pelo Spark foi a capacidade de realizar consultas interativas. O Spark utilizou um interpretador Scala interativo para permitir que os cientistas de dados interagissem com o cluster e experimentassem grandes conjuntos de dados muito mais rapidamente do que a abordagem existente, que consistia em compilar e enviar uma tarefa Hadoop e aguardar os resultados.
Persistiu, no entanto, um problema: a entrada para estes trabalhos Hadoop ou Spark apenas considera dados de uma fonte limitada (não considera novos dados recebidos em tempo de execução). O trabalho é direcionado para uma fonte de entrada, determina como decompor o trabalho em partes ou tarefas paralelas, executa as tarefas em todo o cluster simultaneamente e, por fim, combina os resultados e armazena a saída em algum lugar. Isto funcionou muito bem para tarefas como a geração de índices de PageRank ou regressão logística, mas era a ferramenta errada para um vasto número de outras tarefas que precisam de trabalhar contra uma fonte ilimitada ou de streaming, como a análise de fluxo de cliques ou prevenção de fraudes.
Apache Kafka: Uma plataforma de streaming distribuída
Em 2010, a equipa de engenharia do LinkedIn estava a empreender a tarefa de voltar a arquitetar os alicerces da popular rede social de carreira [Uma Breve História do Kafka, a Plataforma de Mensagens do LinkedIn]. Como muitos sites, o LinkedIn passou de uma arquitetura monolítica para uma com micro serviços interconectados — mas a adoção de uma nova arquitetura baseada num pipeline universal construído sobre um log de commit distribuído chamado Kafka permitiu que o LinkedIn superasse o desafio de lidar com fluxos de eventos quase em tempo real e em escala considerável. Kafka recebeu este nome do engenheiro principal do LinkedIn, Jay Kreps, porque era "um sistema otimizado para escrever", e Jay era um admirador da obra de Franz Kafka.
A principal motivação para o Kafka no LinkedIn era dissociar os micro serviços existentes para que pudessem evoluir de forma mais livre e independente. Anteriormente, qualquer esquema ou protocolo utilizado para permitir a comunicação entre serviços tinha limitado a coevolução dos serviços. A equipa de infraestrutura do LinkedIn percebeu que precisava de mais flexibilidade para evoluir serviços de forma independente. Eles projetaram o Kafka para facilitar a comunicação entre serviços de uma forma que pudesse ser assíncrona e baseada em mensagens. Era necessário oferecer durabilidade (persistir mensagens no disco), ser resiliente a falhas de rede e de nós, oferecer características quase em tempo real e ser escalável horizontalmente para lidar com o crescimento. O Kafka satisfaz estas necessidades entregando um registo distribuído (consulte O Registo: O que todo engenheiro de software deve saber sobre a abstração unificadora de dados em tempo real).
Em 2011, o Kafka foi disponibilizado como open source e muitas empresas começaram a adotá-lo em massa. O Kafka inovou em relação a abstrações anteriores semelhantes de filas de mensagens ou pub-sub, como RabbitMQ e HornetQ, de várias formas importantes:
- Os tópicos Kafka (filas) são particionados para escalar em um cluster de nós Kafka (chamados brokers).
- O Kafka utiliza o ZooKeeper para coordenação de clusters, elevada disponibilidade e failover.
- As mensagens são persistidas no disco por períodos muito longos.
- As mensagens são consumidas por ordem.
- Os consumidores mantêm o seu próprio estado em relação ao deslocamento da última mensagem consumida.
Essas propriedades liberam os produtores de ter que manter o estado em relação ao reconhecimento de qualquer mensagem individual. Agora, as mensagens podem ser transmitidas para o sistema de ficheiros a uma velocidade elevada. Com os consumidores responsáveis por manter a sua própria compensação no tópico, eles poderiam lidar com atualizações e falhas de maneira elegante.
Apache Storm: Sistema de computação em tempo real distribuído
Entretanto, em maio de 2011, Nathan Marz estava a assinar um acordo com o Twitter para adquirir a sua empresa BackType. O BackType era uma empresa que “desenvolveu produtos analíticos para ajudar as empresas a compreender o seu impacto nas redes sociais tanto historicamente como em tempo real” [História do Apache Storm e Lições Aprendidas]. Uma das joias da coroa da BackType era um sistema de processamento em tempo real denominado "Storm". O Storm introduziu um conceito abstrato chamado "topologia", através do qual as operações de fluxo foram simplificadas de forma semelhante ao que o MapReduce tinha feito para o processamento em lote. O Storm ficou conhecido como "o Hadoop em tempo real" e rapidamente alcançou o topo do GitHub e do Hacker News.
Apache Flink: Computações com estado sobre fluxos de dados
Flink também fez a sua estreia pública em maio de 2011. Devendo as suas raízes a um projeto de investigação chamado “Stratosphere” [http://stratosphere.eu/], que foi um esforço colaborativo entre algumas universidades alemãs. A Stratosphere foi concebida com o objetivo de "melhorar a eficiência do processamento de dados massivamente paralelo em plataformas de Infraestrutura como Serviço (IaaS)" [http://www.hpcc.unical.it/hpc2012/pdfs/kao.pdf].
Tal como o Storm, o Flink fornece um modelo de programação para descrever fluxos de dados (chamados de "Jobs" na terminologia do Flink) que incluem um conjunto de fluxos e transformações. O Flink inclui um motor de execução para paralelizar eficazmente o trabalho e agendá-lo em todo um cluster gerido. Uma propriedade única do Flink é que o modelo de programação facilita tanto fontes de dados limitadas como ilimitadas. Isto significa que a diferença na sintaxe entre um trabalho de execução única que obtém dados de uma base de dados SQL (o que pode ter sido tradicionalmente um trabalho em lote) versus um trabalho de execução contínua que opera sobre dados de streaming de um tópico Kafka é mínima. O Flink entrou no projeto de incubação Apache em março de 2014 e foi aceite como um projeto de nível superior em dezembro de 2014.
Em fevereiro de 2013, a versão alfa do Spark Streaming foi lançada com o Spark 0.7.0. Em setembro de 2013, a equipa do LinkedIn tornou open source a sua estrutura de processamento de fluxo “Samza” com este post.
Em maio de 2014, o Spark 1.0.0 foi lançado, incluindo a estreia do Spark SQL. Embora a versão atual do Spark na época oferecesse apenas capacidade de streaming ao dividir uma fonte de dados em "micro-lotes", a base para a execução de consultas SQL como aplicações de streaming já estava estabelecida.
Apache Beam: Um modelo de programação unificado para tarefas em lote e em streaming
Em 2015, um coletivo de engenheiros da Google publicou um artigo intitulado The Dataflow Model: A Practical Approach to Balancing Correctness, Latency, and Cost in Massive-Scale, Unbounded, Out-of-Order Data Processing. Uma implementação do modelo Dataflow foi disponibilizada comercialmente na Google Cloud Platform em 2014. O SDK principal deste trabalho, bem como vários conectores de IO e um executor local, foram doados à Apache e tornaram-se a versão inicial do Apache Beam em junho de 2016.
Um dos pilares do modelo Dataflow (e do Apache Beam) é que a representação do pipeline em si é abstraída da escolha do motor de execução. No momento da redação, o Beam é capaz de compilar o mesmo código de pipeline para direcionar Flink, Spark, Samza, GearPump, Google Cloud Dataflow e Apex. Isso oferece ao utilizador a opção de evoluir o motor de execução posteriormente, sem alterar a implementação da tarefa. Um motor de execução “Direct Runner” também está disponível para testes e desenvolvimento no ambiente local.
Em 2016, a equipa Flink apresentou o Flink SQL. O Kafka SQL foi anunciado em agosto de 2017 e, em maio de 2019, um grupo de engenheiros da Apache Beam, Apache Calcite e Apache Flink apresentou “One SQL to Rule Them All: An Efficient and Syntactically Idiomatic Approach to Management of Streams and Tables” rumo a um SQL de streaming unificado.
Para onde nos dirigimos
As ferramentas disponíveis para os arquitetos de software que projetam o pipeline de dados continuam a evoluir a uma velocidade cada vez maior. Estamos a observar motores de fluxo de trabalho, como Airflow e Prefect, que estão a integrar sistemas como Dask para permitir que os utilizadores paralelizem e agendem cargas de trabalho massivas de aprendizagem automática no cluster. Concorrentes emergentes como o Apache Pulsar e o Pravega estão a competir com o Kafka para assumir a abstração de armazenamento do fluxo. Também estamos a ver projetos como Dagster, Kafka Connect e Siddhi a integrar componentes existentes e a fornecer abordagens inovadoras para visualizar e conceber o pipeline de dados. O rápido ritmo de desenvolvimento nessas áreas torna este um momento muito empolgante para criar aplicações com uso intensivo de dados.
Se trabalhar com este tipo de tecnologias lhe interessa, encorajamo-lo a entrar em contacto! Estamos a contratar em várias funções de engenharia e em várias localizações.

Robert Boyd é Principal Software Engineer na Barracuda Networks. A sua área de foco atual é o armazenamento seguro e a pesquisa de email em escala.
Os favoritos dos leitores de 2021
O final do ano é sempre um excelente momento para mostrar alguns dos nossos conteúdos favoritos. Estas são as publicações do blogue Barracuda mais populares de 2020. Esperamos que as aprecie!
Ransomware e violações de dados
- Como os hackers utilizam o phishing em ataques de ransomware
- Principais preocupações das organizações de saúde em relação ao backup do Office 365
- 3 passos críticos para proteger contra ransomware
- Ataque cibernético à Colonial Pipeline revela o impacto económico do ransomware
Pesquisa
- Tipos de ameaça por e-mail: phishing de URL
- Threat Spotlight: Tendências de Ransomware
- Threat Spotlight: Ataques de Isco
Relatórios Especiais
- O estado da segurança da rede em 2021
- O estado da segurança de aplicações em 2021
- Redes de cloud: a entrar em hiper velocidade
- O estado do backup do Office 365
- Insights sobre o número crescente de ataques automatizados
Abaixo da Superfície
- Abaixo da Superfície: Por que precisa de uma estratégia de backup nativa da Cloud
- Abaixo da Superfície: Avançar as Mulheres na Tecnologia
- Abaixo da Superfície: Secure Access Service Edge com Sinan Eren
Barracuda
- Barracuda nomeada Visionária no Quadrante Mágico do Gartner® 2021 para Firewalls de Rede

- Barracuda homenageada pela Comparably para Melhor Cultura Empresarial
- Três inovações de produtos emocionantes anunciadas na Secured.21
- Nos bastidores da colaboração entre a Barracuda e a Microsoft no Cloud-to-Cloud Backup
- Barracuda nomeada para a lista de Segurança 100 da CRN de 2021
- Barracuda vence o prémio de Melhor Serviço ao Cliente nos Prémios SC de 2021
Favoritos antigos
Algumas questões nunca desaparecem. Porque é que não posso usar o meu Email pessoal para o trabalho? O que quer dizer com "este spam não é spam"? Estas publicações são as favoritas dos leitores ano após ano.
- Os riscos comerciais das contas de email pessoais
- Ham vs Spam: Qual é a diferença?
- Vetores de ameaça – o que são e por que precisa saber sobre eles?
Ansiosos por 2022
Teremos mais conteúdos excelentes dos nossos especialistas, incluindo Olesia, Tushar, Anastasia, Jonathan, Fleming e outros. Publicamos várias vezes por semana e, caso deseje ser notificado quando tivermos novos conteúdos, inscreva-se no nosso blog para receber resumos por email das últimas publicações. Novos episódios de Below the Surface são transmitidos a cada poucas semanas, e pode visualizar os episódios do nosso site de arquivamento.
Os melhores votos de um feliz ano novo, de todos nós na Barracuda.

Christine Barry é blogueira chefe sénior e gerente de redes sociais na Barracuda. Antes de ingressar na Barracuda, Christine atuou como engenheira de campo e gestora de projetos para clientes K12 e SMB por mais de 15 anos. Ela possui várias credenciais em tecnologia e gestão de projetos, um bacharelato em artes e um mestrado em administração de empresas. Ela é formada pela Universidade de Michigan.
Entre em contacto com Christine no LinkedIn aqui.
Registo de eventos altamente escalável para AWS
A maioria das aplicações gera eventos de configuração e de acesso. É importante que os administradores tenham visibilidade sobre estes eventos. O Serviço de Segurança de E-mail Barracuda fornece transparência e visibilidade em muitos destes eventos para ajudar os administradores a afinar e compreender o sistema. Por exemplo, saber quem iniciou sessão na conta e quando. Ou saber quem adicionou, alterou ou eliminou a configuração de uma determinada política.
Para construir este sistema distribuído e pesquisável, surgem muitas questões, tais como:
- Como deve gravar estes logs de todas as aplicações, serviços e máquinas num local central?
- Qual deve ser o formato padrão dos ficheiros de log?
- Por quanto tempo deve reter esses registos?
- Como deve correlacionar eventos de diferentes aplicações?
- Como fornece um mecanismo de pesquisa simples e rápido através de uma interface de utilizador para o administrador?
- Como disponibiliza estes logs através de uma API?
Quando se pensa em um mecanismo de pesquisa distribuído, a primeira coisa que vem à mente é o Elasticsearch. É altamente escalável com pesquisa quase em tempo real e está disponível como um serviço totalmente gerido na AWS. Assim, a jornada começou com a ideia de armazenar esses logs de eventos no Elasticsearch e todas as diferentes aplicações enviando logs para o Elasticsearch usando o Kinesis Data Firehose.
Componentes envolvidos nesta arquitetura
- Kinesis Agent – O Amazon Kinesis Agent é uma aplicação Java independente que oferece uma forma fácil de recolher e enviar dados para o Kinesis Data Firehose. O agente monitoriza continuamente os ficheiros de log de eventos nas instâncias do EC2 Linux e envia-os para o fluxo de entrega do Kinesis Data Firehose configurado. O agente gere a rotação de ficheiros, pontos de verificação e repetições em caso de falhas. Fornece todos os seus dados de forma fiável, atempada e simples. Nota: Se a aplicação que precisa de escrever no Kinesis Firehose for um contentor Fargate, será necessário um contentor Fluentd. No entanto, este artigo foca-se em aplicações que correm em instâncias Amazon EC2.
- Kinesis Data Firehose – O método de inserção direta do Amazon Kinesis Data Firehose pode gravar dados formatados em JSON no Elasticsearch. Desta forma, não armazena dados no fluxo.
- S3 – Um bucket S3 pode ser usado para fazer backup de todos os registos ou dos registos que falham na entrega ao Elasticsearch. As políticas de ciclo de vida também podem ser configuradas para o arquivamento automático dos registos.
- Elasticsearch – Elasticsearch hospedado na Amazon. O acesso ao Kibana pode ser ativado para auxiliar na consulta e pesquisa dos logs para fins de depuração.
- Curator – A AWS recomenda usar o Lambda e o Curator para gerir os índices e instantâneos do cluster Elasticsearch. A AWS tem mais detalhes e exemplos de implementação que podem ser encontrados aqui
- Interface REST API – Pode criar uma API como uma abstração para o Elasticsearch que se integra bem com a interface do utilizador. As arquiteturas de micro serviços orientadas por API são comprovadamente as melhores em muitos aspetos, como segurança, conformidade e integração com outros serviços.

Escalonamento
- Kinesis Data Firehose: Por predefinição, os fluxos de entrega firehose podem ser escalonados até 1 000 registos/segundo ou 1 MiB/segundo para a região Leste dos EUA (Ohio). Este é um limite flexível e pode ser aumentado até 10 000 registos/segundo. Isto é específico da região.
- Elasticsearch: O cluster Elasticsearch pode ser escalado tanto em termos de armazenamento quanto de poder de computação na AWS. Também é possível realizar atualizações de versão. O Amazon ES utiliza um processo de implementação blue/green ao atualizar domínios. Isso significa que o número de nós no cluster pode aumentar temporariamente enquanto as suas alterações são aplicadas.
Vantagens desta Arquitetura
- A arquitetura do pipeline é completamente gerida de forma eficaz e requer muito pouca manutenção.
- Se o cluster Elasticsearch falhar, o Kinesis Firehose pode reter registos por até 24 horas. Além disso, os registos que não são entregues também são copiados para o S3.
As probabilidades de perda de dados são baixas com estas opções disponíveis.
- O controlo de acesso detalhado é possível tanto para o Kibana como para a API do Elasticsearch através de políticas de IAM.
Deficiências
- Os preços devem ser cuidadosamente considerados e monitorizados. O Kinesis Data Firehose pode lidar com grandes quantidades de ingestão de dados com facilidade e, se um agente malicioso começar a registar grandes quantidades de dados, o Kinesis Data Firehose irá entregá-los sem problemas. Isso pode acarretar custos elevados.
- A integração do Kinesis Data Firehose com o Elasticsearch é suportada apenas para clusters Elasticsearch não-vpc.
- Atualmente, o Kinesis Data Firehose não pode entregar logs para clusters Elasticsearch que não sejam hospedados pela AWS. Se pretender hospedar clusters do Elasticsearch por conta própria, esta configuração não funcionará.
Conclusão
Se procura uma solução totalmente gerida e que (na sua maioria) escala sem intervenção, esta seria uma boa opção a considerar. O backup automático para o S3 com políticas de ciclo de vida também resolve facilmente o problema de retenção e arquivamento de logs.

Sravanthi Gottipati é Engineering Manager de segurança de e-mail na Barracuda Networks. Pode conectar-se com ela no LinkedIn aqui.
DJANGO-EB-SQS: Uma forma mais fácil para as aplicações Django comunicarem com AWS SQS
Os serviços AWS, como Amazon ECS, Amazon S3, Amazon Kinesis, Amazon SQS e Amazon RDS, são amplamente utilizados em todo o mundo. Na Barracuda, utilizamos AWS Simple Queue Service (SQS) para gerir as mensagens dentro e entre os micro serviços que desenvolvemos na framework Django.
O AWS SQS é um serviço de fila de mensagens que pode “enviar, armazenar e receber mensagens entre componentes de software em qualquer volume, sem perder mensagens ou exigir que outros serviços estejam disponíveis.” O SQS foi concebido para ajudar as organizações a dissociar aplicações e dimensionar serviços, sendo a ferramenta perfeita para o nosso trabalho com micro serviços. No entanto, cada novo micro serviço baseado em Django ou dissociação de um serviço existente utilizando AWS SQS exigia que duplicássemos o nosso código e lógica para comunicar com o AWS SQS. Isso resultou em muito código repetido e encorajou a nossa equipa a construir esta biblioteca GitHub: DJANGO-EB-SQS
Django-EB-SQS é uma biblioteca Python destinada a ajudar os desenvolvedores a integrar rapidamente o AWS SQS com aplicações existentes e/ou novas baseadas em Django. A biblioteca cuida das seguintes tarefas:
- Serialização dos dados
- Adicionar lógica de atraso
- Polling contínuo da fila
- Desserializar os dados de acordo com os padrões da AWS SQS e/ou utilizar bibliotecas de terceiros para comunicar com a AWS SQS.
Em suma, abstrai toda a complexidade envolvida na comunicação com o AWS SQS e permite que os programadores se concentrem apenas na lógica central do negócio.
A biblioteca é baseada no Django ORM framework e na boto3 library.
Como o utilizamos
A nossa equipa trabalha numa solução de proteção de e-mail que utiliza inteligência artificial para detetar spear phishing e outros ataques de social engineering. Integramos com a conta Office 365 do nosso cliente e recebemos notificações sempre que ele recebe novos Emails. Uma das tarefas consiste em determinar se o novo Email está livre de qualquer fraud ou não. Ao receber essas notificações, um dos nossos serviços (Figura 1: Serviço 1) comunica-se com o Office 365 através da API Graph e obtém esses Emails. Para processamento posterior desses Emails e para disponibilizá-los para outros serviços, eles são enviados para a fila AWS SQS (Figura 1: queue_1).

Figura 1
Vamos analisar um caso de uso simples de como utilizamos a biblioteca nas nossas soluções. Um dos nossos serviços (Figura 1: Serviço 2) é responsável por extrair cabeçalhos e conjuntos de recursos de Emails individuais e disponibilizá-los para outros serviços consumirem.
O serviço 2 está configurado para escutar a queue_1 para recuperar os corpos de Email brutos.
Vamos supor que o Serviço 2 realiza as seguintes ações:
# Consumir mensagens de email da queue_1
…
# extrair cabeçalhos e conjuntos de funcionalidades dos Email
…
# submeter uma tarefa
processar_mensagem.atraso(id_locatário=, id_e-mail=, cabeçalhos=, id_locatário=, conjunto_de_recursos=, ….)
Este método process_message não será chamado de forma síncrona, mas sim colocado em fila como uma tarefa e será executado assim que um dos trabalhadores o selecionar. O trabalhador aqui pode ser do mesmo serviço ou de um serviço diferente. O autor da chamada do método não precisa preocupar-se com o comportamento subjacente e como a tarefa será executada.
Vamos ver como o método process_message e definido como uma tarefa.
importar tarefa de eb_sqs.decorators
@task(queue_name='queue_2′, max_retries=3)
def process_message(tenant_id: int, email_id: str, headers: List[dict], feature_set: List[dict], …) :
tente:
# executar alguma ação usando cabeçalhos e conjuntos de funcionalidades
# também pode enfileirar tarefas adicionais, se necessário
except(OperationalError, InterfaceError) as exc:
tente:
process_message.retry()
exceto MaxRetriesReachedException:
logger.error('MaxRetries alcançado para Service2:process_message ex: {exc}')
Quando decoramos o método com o decorador de tarefa, o que acontece por trás é que ele adiciona dados adicionais, como o método de chamada, o método de destino, seus argumentos e alguns metadados adicionais antes de serializar a mensagem e enviá-la para a fila AWS SQS. Quando a mensagem é consumida da fila por um dos trabalhadores, ela contém todas as informações necessárias para executar a tarefa: qual método chamar, quais parâmetros passar e assim por diante.
Também podemos tentar novamente a tarefa em caso de exceção. No entanto, para evitar um cenário de loop infinito, podemos definir um parâmetro opcional max_retries, onde podemos parar o processamento depois de atingir o número máximo de tentativas. Podemos então registar o erro ou enviar a tarefa para uma fila de mensagens não entregues para análise adicional.
O AWS SQS permite atrasar o processamento da mensagem em até 15 minutos. Podemos adicionar uma funcionalidade semelhante à nossa tarefa passando o parâmetro de atraso:
process_message.delay(email_id=, headers=, …., delay=300) # atrasando em 5 minutos
A execução das tarefas pode ser realizada executando o comando Django process_queue. Isso permite ouvir uma ou mais filas, ler as filas indefinidamente e executar as tarefas à medida que elas chegam:
python manage.py process_queue –queues
Acabámos de ver como esta biblioteca facilita a comunicação dentro de um serviço ou entre serviços através das filas AWS SQS.
Mais detalhes sobre como configurar a biblioteca com as definições do Django, a capacidade de ouvir várias filas, a configuração de desenvolvimento e muitas outras funcionalidades podem ser encontrados aqui.
Contribuir
Se pretender contribuir para o projeto, consulte aqui: DJANGO-EB-SQS

Rohan Patil é Principal Software Engineer na Barracuda Networks. Atualmente, ele está a trabalhar no Barracuda Sentinel, uma proteção baseada em IA contra phishing e apropriação de contas. Ele trabalhou nos últimos cinco anos com tecnologias de cloud e, na última década, em várias funções relacionadas ao desenvolvimento de software. Ele possui um mestrado em Ciência da Computação pela California State University e um bacharelato em Ciência da Computação pela Universidade de Mumbai, Índia.
Utilizar o GraphQL para APIs robustas e flexíveis
O design de API é uma área onde pode haver muita controvérsia entre os desenvolvedores de aplicações cliente e os desenvolvedores de back-end. As APIs REST permitiram-nos projetar servidores sem estado e acesso estruturado a recursos por mais de duas décadas, e continuam a servir a indústria, principalmente devido à sua simplicidade e curva de aprendizagem moderada.
O REST foi desenvolvido por volta do ano 2000, quando as aplicações cliente eram relativamente simples e o ritmo de desenvolvimento não era tão rápido como é hoje.
Com uma abordagem tradicional baseada em REST, o design seria baseado no conceito de recursos que um determinado servidor gere. Em seguida, normalmente utilizamos verbos HTTP, como GET, POST, PATCH, DELETE, para realizar operações CRUD nesses recursos.
Desde os anos 2000, várias coisas mudaram:
- O aumento da utilização de aplicações de página única e aplicações móveis criou a necessidade de um carregamento eficiente de dados.
- Muitas das arquiteturas de back-end passaram de monolíticas para arquiteturas de micro serviços para ciclos de desenvolvimento mais rápidos e eficientes.
- Uma variedade de clientes e consumidores é necessária para as APIs. O REST dificulta a criação de uma API que suporte vários clientes, pois retornaria uma estrutura de dados fixa.
- As empresas esperam lançar funcionalidades no mercado mais rapidamente. Se for necessário fazer uma alteração no lado do cliente, muitas vezes é preciso um ajuste no lado do servidor com REST, o que leva a ciclos de desenvolvimento mais lentos.
- A atenção crescente na experiência do utilizador frequentemente leva ao design de visualizações/widgets que necessitam de dados de múltiplos servidores de recursos da API REST para serem renderizados.
GraphQL como uma alternativa ao REST
GraphQL é uma alternativa moderna ao REST que visa resolver várias deficiências, e a sua arquitetura e ferramentas são construídas para oferecer soluções para as práticas contemporâneas de desenvolvimento de software. Permite que os clientes especifiquem exatamente quais dados são necessários e permite a obtenção de dados de vários recursos em uma única solicitação. Funciona mais como RPC, com consultas nomeadas e mutações em vez de ações obrigatórias padrão baseadas em HTTP. Isso coloca o controlo onde ele deve estar, com o programador da API backend a especificar o que é possível e o cliente/consumidor da API a especificar o que é necessário.
Aqui está um exemplo de consulta GraphQL, que foi uma revelação para mim quando me deparei com isso pela primeira vez. Suponha que estamos a desenvolver um site de microblogging e precisamos consultar as 50 publicações mais recentes.
query recentPosts (count: 50, offset: 0) {
id
title
tags
content
author {
id
name
profile {
email
interests
}
}
}
A consulta GraphQL acima tem como objetivo solicitar:
- 50 publicações recentes
- ID, título, tags e conteúdo de cada publicação do blogue
- Informações do autor contendo id, nome e informações do perfil.
Se tivermos que usar uma abordagem tradicional de API REST para isso, o cliente precisaria fazer 51 solicitações. Se as publicações e os autores forem considerados recursos separados, isso significa um pedido para obter 50 publicações recentes e, em seguida, 50 pedidos para obter informações sobre o autor para cada publicação. Se as informações do autor puderem ser incluídas nos detalhes da publicação, isso também poderia ser uma solicitação com a API REST. No entanto, na maioria dos casos, quando modelamos os nossos dados utilizando as melhores práticas de normalização de bases de dados relacionais, gerimos as informações do autor numa tabela separada, o que faz com que as informações do autor sejam um recurso separado da API REST.
Aqui está a parte interessante do GraphQL. Digamos que, numa visualização móvel, não temos espaço suficiente no ecrã para exibir tanto o conteúdo da publicação como as informações do perfil do autor. Essa consulta agora poderia ser:
query recentPosts(count: 50, offset: 0) {
id
title
tags
author {
id
name
}
}
O cliente móvel agora especifica as informações que deseja, e a API GraphQL fornece exatamente os dados solicitados, nada mais e nada menos. Não tivemos de fazer quaisquer ajustes no lado do servidor, nem o nosso código do lado do cliente teve de mudar significativamente, e o nosso tráfego de rede entre o cliente e o servidor é ideal.
O ponto a destacar aqui é que o GraphQL nos permite projetar APIs flexíveis com base nos requisitos do lado do cliente, em vez de uma perspetiva de gestão de recursos do lado do servidor. A perceção geral é que o GraphQL faz sentido apenas para arquiteturas complexas que envolvem várias dezenas de micro serviços. Isso é verdade até certo ponto, considerando que há uma curva de aprendizagem com o GraphQL em comparação com as arquiteturas REST API. Mas essa lacuna está a diminuir, com um investimento intelectual e financeiro significativo da fundação emergente de fornecedores neutros.
A Barracuda é uma das primeiras a adotar arquiteturas GraphQL. Se este blog despertou o seu interesse, por favor, acompanhe este espaço para os meus próximos blogs, onde aprofundarei mais detalhes técnicos e benefícios arquitetónicos.

Vinay Patnana é o Engineering Manager do serviço de segurança de e-mail da Barracuda. Nesta função, ele auxilia no design e desenvolvimento de serviços de escalabilidade das soluções de email da Barracuda.
Vinay possui um mestrado em Ciência da Computação pela North Carolina State University e um bacharelato em Engenharia pelo BIT Mesra, na Índia. Ele está na Barracuda há vários anos e possui mais de uma década de experiência trabalhando com diversas variedades de stacks técnicos. Pode conectar-se com ele no LinkedIn aqui.
Nota: Este blog foi originalmente publicado no Databricks Company Blog.
74% das organizações a nível global foram vítimas de um ataque de phishing. A Barracuda Networks é líder global em soluções de segurança, entrega de aplicações e proteção de dados, ajudando os clientes a combater ataques de phishing em grande escala. A Barracuda desenvolveu um poderoso motor de inteligência artificial que utiliza análise comportamental para detetar ataques e manter os agentes maliciosos afastados.
Lidar com e-mails de phishing é difícil devido à sofisticação que os atacantes utilizam atualmente na criação de e-mails maliciosos. A Barracuda Networks utiliza a aprendizagem automática para avaliar e identificar mensagens maliciosas e proteger os seus clientes. Usando ML na Plataforma Databricks Lakehouse, a equipa Barracuda conseguiu mover-se muito mais rápido e está agora a bloquear dezenas de milhares de e-mails maliciosos diariamente de chegarem a milhões de caixas de correio em milhares de clientes.
Fornecendo proteção abrangente de segurança de e-mail
A equipa da Barracuda é dedicada a detetar ataques de phishing e fornecer segurança aos clientes. Eles conseguem isso trabalhando com o Microsoft Office 365 e analisando o fluxo de emails em busca de possíveis ameaças. Se um ataque for detetado, ele é imediatamente removido da caixa de correio antes que os utilizadores possam vê-lo.
Proteção contra falsificação de identidade
Um dos principais produtos que a Barracuda oferece é a proteção contra falsificação de identidade. A falsificação de identidade ocorre quando atores maliciosos disfarçam as suas mensagens como provenientes de uma fonte oficial, como um executivo ou serviço conhecido. Os atacantes podem utilizar este ataque para aceder a informações confidenciais, representando um risco significativo para indivíduos e organizações.
A proteção contra falsificação de identidade está focada em dissuadir ataques de phishing direcionados. Estas tentativas não são enviadas em grandes quantidades, ao contrário dos emails de spam. Para enviar um ataque direcionado, o atacante deve ter detalhes pessoais sobre o destinatário para personalizá-lo, como a sua profissão ou área de trabalho. Para identificar e bloquear ataques de phishing por falsificação de identidade, a equipa teve de criar um conjunto de modelos de classificação e implementá-los em produção para os nossos utilizadores.
Dificuldades com a Engenharia de Funcionalidades
Para treinar adequadamente os nossos modelos de AI para detetar ataques de phishing e de falsificação de identidade, a Barracuda necessitou de utilizar os dados corretos e fazer engenharia de características sobre esses dados. Os dados incluíam texto de email, que poderia ser um sinal de um ataque de phishing, e dados estatísticos, como detalhes do remetente do email. Por exemplo, se um utilizador receber um email de fatura de alguém que não enviou um email semelhante ao longo dos últimos meses, isto poderia sinalizar um risco de um ataque de phishing. Antes da integração com o Databricks, a construção de funcionalidades era mais difícil com os dados rotulados distribuídos por vários meses, particularmente com as funcionalidades estatísticas. Além disso, manter o controlo das funcionalidades quando o nosso conjunto de dados cresce em tamanho é desafiante.
Implementação lenta
A nossa equipa manteve o código e o modelo separados e teve de duplicar o código de pesquisa para o ambiente de produção, o que exigiu tempo e energia. Primeiro, passaríamos cada email recebido pelo código de pré-processamento e, em seguida, passaríamos os emails pré-processados para o modelo para inferência.
Barracuda encontra sucesso ao usar Databricks
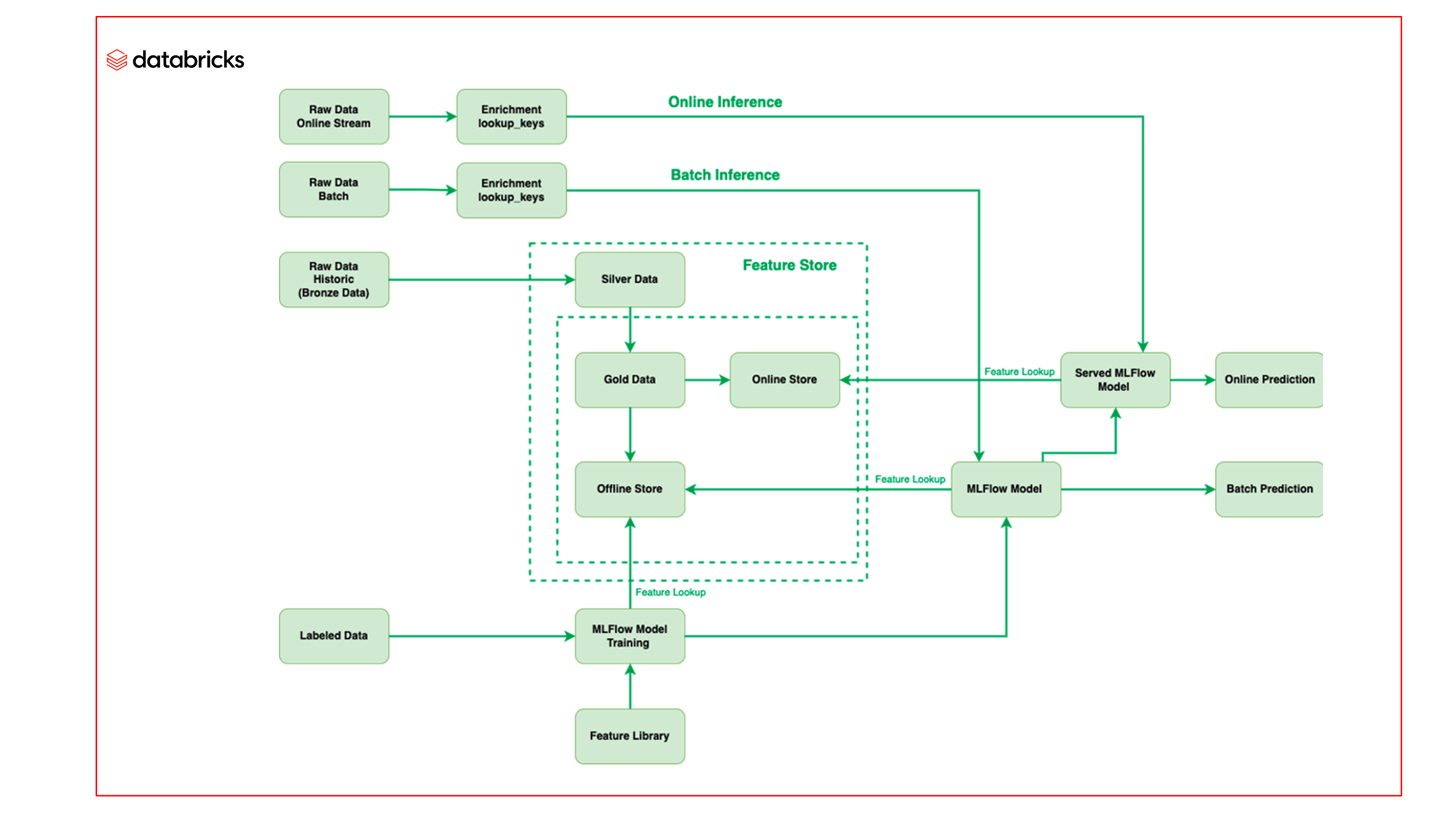
A equipa da Barracuda utilizou a aprendizagem automática na Databricks Lakehouse Platform, especificamente usando o Databricks Feature Store e Managed MLflow, para melhorar o processo de ML e implementar modelos de melhor qualidade mais rapidamente.

Feature Store
O Databricks Feature Store funciona como o repositório único para todos os recursos utilizados pela equipa da Barracuda. Para criar e manter recursos estatísticos que são constantemente atualizados com novos lotes de emails recebidos, foram utilizados dados rotulados na engenharia de recursos. Como o Feature Store é construído sobre o Delta, não é necessário processamento extra para converter dados rotulados em recursos, e os recursos permanecem atuais. As funcionalidades são mantidas num repositório offline, e instantâneos dessas informações são então disponibilizados online para uso em inferências online. Além disso, ao integrar o Databricks Feature Store com o MLflow, esses recursos podem ser prontamente chamados a partir dos modelos no MLflow, e o modelo pode obter o recurso simultaneamente com a recuperação do recurso quando o email chega para inferência.
Operações de Aprendizagem Automática Mais Rápidas
A outra vantagem é a gestão de todos os modelos de aprendizagem automática no MLflow. Com o MLflow, a equipa pode mover todo o código para dentro do modelo, permitindo que o e-mail passe pelo modelo para inferência, em vez de pré-processar através do código como era feito antes, tornando mais simples e mais rápido inferir. Ao utilizar o MLflow, a equipa da Barracuda consegue criar modelos totalmente auto-empacotados. Esta capacidade reduz significativamente o tempo que a equipa dedica ao desenvolvimento de modelos de ML.
Maior taxa de deteção
Com o Databricks, a equipa tem mais tempo e mais recursos computacionais, permitindo-lhes publicar frequentemente novas tabelas no Delta, atualizar as funcionalidades diariamente e utilizá-las para determinar se um email recebido é um ataque ou não. Isso resulta em maior precisão na deteção de ataques de phishing e melhora a proteção e a satisfação do cliente.
Impacto
Com a ajuda da Databricks, a Barracuda protege os utilizadores contra ataques por e-mail em todo o mundo. Todos os dias, a equipa impede que dezenas de milhares de e-mails maliciosos cheguem às caixas de correio dos clientes. A equipa está ansiosa por continuar a implementar novas funcionalidades da Databricks para melhorar ainda mais a experiência dos nossos clientes.

{kind=link}
Mohamed Afifi Ibrahim é Engenheiro Principal de Aprendizagem Automática na Barracuda.